
JAX-Privacy y el nuevo estándar de IA auditable: qué cambia para ingenieros y DPOs (Parte I)

La IA tiene un problema de memoria (y por fin tenemos una forma de medirlo)
Hace unos días Google anunció JAX-Privacy 1.0 y, honestamente, me quedé mirando la pantalla un rato largo. No porque sea tecnología espacial —que en cierto sentido lo es— sino porque por primera vez en mucho tiempo sentí que alguien estaba atacando el problema correcto de la forma correcta,un problema de fondo y crítico para quienes trabajamos con datos sensibles y buscamos avanzar en la innovaciòn con IA, la protección de datos..
Déjame explicarte por qué esto me tiene tan entusiasmado.
El elefante en la sala de servidores.
Llevamos años con el mismo mantra: “para que la IA funcione, necesitamos datos. Muchos datos.” incluso con otras frases para graficar la importancia de los datos en la IA, “ Los datos son la nafta de la IA”. Es cierto. Los modelos que recomiendan películas, detectan fraude o resumen textos viven de grandes volúmenes de información real. El tema es que cuando esos datos son de personas reales, con vidas reales, coexistiendo en una infraestructura de terceros o incluso on premise el asunto se pone complicado.
Acá está el problema que nadie quiere decir en voz alta: tus modelos de IA están memorizando cosas que no deberían, guardan registro que pueden poner en riesgo la información sensible. No es teoría conspirativa, es matemática pura. Un modelo de machine learning puede aprender y recordar fragmentos muy específicos de los datos con los que lo entrenaste. Y bajo ciertas condiciones, puede “escupirlos” de vuelta.
Solo por un momento, imaginemos esto: un hospital de Buenos Aires o de Córdoba busca entrenar un modelo para ayudar con diagnósticos predictivos, y sabemos que la única forma de hacerlo es usando miles de historiales clínicos. Genial. Pero ese modelo podría terminar memorizando detalles muy específicos de pacientes individuales, donde directamente se ve vulnerada la información sensible de los pacientes.Otro ejemplo real y que hoy, en estos momentos seguramente está sucediendo, un banco entrena un modelo de crédito con transacciones detalladas de clientes para segmentar usuarios y prever comportamiento financiero. Perfecto. Excepto que el modelo puede estar guardando información sensible de personas específicas como si fuera una base de datos comprimida.
Para alguien que trabaja en cumplimiento normativo —y puedo dar fé, he estado ahí, en ese rol— esto es una pesadilla. Porque según el RGPD, no alcanza con poner un par de frases bonitas en la política de privacidad ni con “pseudonimizar el dataset”. El artículo 25 exige protección de datos “desde el diseño y por defecto”. Y cuando hablás de proyectos de IA con datos sensibles, necesitás hacer una Evaluación de Impacto (DPIA) antes de arrancar.
¿El resultado? En el sector público, proyectos piloto eternos que nunca llegan a producción porque nadie se atreve a firmar. En el privado, miedo a innovar: “mejor no toques esos datos, no sea que haya un problema con el regulador”.
En este punto entra en juego el artículo 25 del RGPD, relativo a la protección de datos desde el diseño y por defecto (data protection by design and by default). Para mí, aquí es donde empieza a cobrar verdadero sentido el ciclo completo de vida de un producto, que debe pensarse desde el inicio incorporando la seguridad de la información y la protección de los datos personales, y no como un requisito que se agrega al final.
Esto implica diseñar productos digitales considerando la protección de datos desde el momento en que se conciben, pasando por la planificación, la arquitectura técnica, el desarrollo y la operación, asegurando que las decisiones de diseño respeten principios como la minimización de datos, la limitación de la finalidad y la confidencialidad.
La aplicación práctica de este enfoque, especialmente al dirigir equipos de desarrollo y trabajar en productos digitales que tratan datos personales, la voy a abordar en un artículo específico más adelante, donde profundizaré en sus implicancias técnicas, organizativas y normativas.
Entra JAX-Privacy (sin el hype innecesario)
Google acaba de lanzar JAX-Privacy 1.0, y aunque suene a “otra librería más”, esto es diferente. Es de código abierto, está pensado para producción real, y ataca el problema de raíz, no simplemente un addon de un producto de google, y eso se valora.
La idea central es privacidad diferencial. Si nunca escuchaste el término, la explicación simple es esta: entrenar tu modelo de tal forma que matemáticamente —no “más o menos” o “quizás”, sino matemáticamente— sea casi imposible distinguir si los datos de una persona específica estuvieron o no en el dataset de entrenamiento.
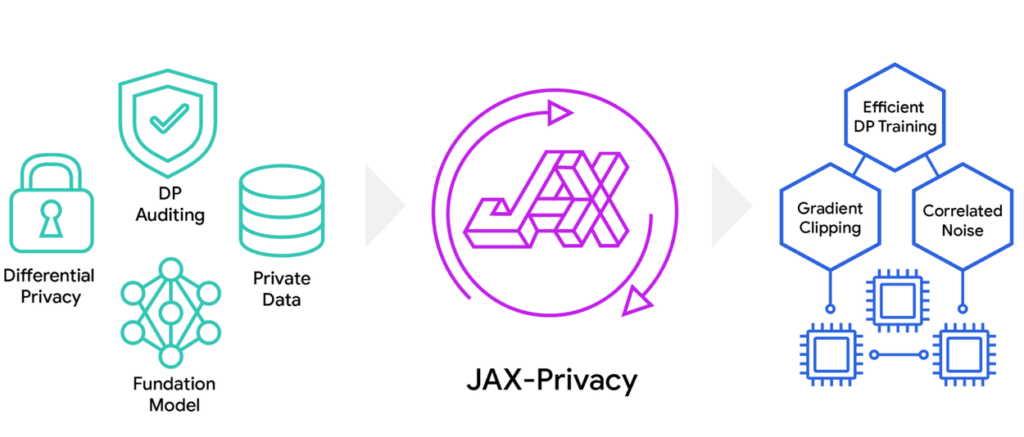
JAX-Privacy te da las herramientas para hacer esto a escala industrial. No es un experimento académico. Google lo usó para entrenar VaultGemma, un modelo de lenguaje grande (de esos con miles de millones de parámetros) con privacidad diferencial desde cero.
Acá viene lo más técnico pero no menos importante: la librería corre sobre JAX, que es la base de computación numérica de alta performance de Google (piensa en algo muy rápido para entrenar modelos en GPUs y TPUs). JAX-Privacy agrega encima todos los componentes que necesitás para entrenar con privacidad diferencial:
-
- Recorte de gradientes
-
- Generación de ruido calibrado
-
- Algoritmos como DP-SGD (Stochastic Gradient Descent con privacidad diferencial)
-
- Y lo más importante: herramientas para medir y auditar cuánta privacidad estás garantizando
Ese último punto es el game-changer. Porque la privacidad diferencial tiene algo que ninguna otra técnica tiene: te permite calcular un “presupuesto de privacidad” y su alcance (epsilon y delta, si querés los nombres técnicos). Son números que te dicen cuánto riesgo de fuga de información tenés. No “poco riesgo” o “riesgo bajo”, sino un número que podés medir, auditar y defender.
¿Por qué esto no existía antes a esta escala dentro de soluciones AI y sus modelos?.
La privacidad diferencial no es nueva. El concepto lleva más de 15 años dando vueltas en papers académicos y algunos desarrollos de prototipos en la industria. El problema siempre fue llevarlo a la práctica con modelos modernos.
Entrenar un modelo grande ya es complicado. Entrenar uno grande CON privacidad diferencial era, hasta hace poco, algo que solo podían hacer equipos de investigación con recursos gigantes y mucha paciencia. Los costos computacionales se disparaban, la precisión del modelo caía, y el código era un experimento frágil que explotaba si lo mirabas mal.
JAX-Privacy cambia eso. No porque haga magia, sino porque está diseñado desde cero para aprovechar la arquitectura de JAX: compilación justo-a-tiempo, paralelismo en hardware acelerado, optimizaciones que hacen que el overhead de la privacidad diferencial sea manejable.
Y no está solo. Hay un ecosistema creciendo alrededor de esto. Proyectos como TensorFlow Privacy, bibliotecas para aprendizaje federado, herramientas que combinan privacidad diferencial con computación segura multipartita (MPC). Secret-Learn, por ejemplo, ya mostraba que se podían reconstruir algoritmos clásicos de scikit-learn con aceleración JAX y varias capas de protección.
La diferencia es que JAX-Privacy es Google poniéndole el sello de “esto está listo para producción”. Y cuando Google dice eso, los equipos de ingeniería del mundo empiezan a escuchar.
Lo que realmente está cambiando.
Déjame contarte cómo eran las conversaciones antes. Cada vez que llegaba un proyecto de IA al área de compliance, o cuando me tocaba evaluar uno que involucra datos personales, el guión era siempre el mismo:
Equipo de Data/IA:Necesitamos estos datasets para entrenar el modelo.”
Yo consultando con equipos compliance (o el equipo legal): “Ok, ¿y cómo garantizamos la privacidad de esa gente?”
Equipo de Data/IA :”Ehh… vamos a anonimizar. Y usar técnicas de seguridad. Acceso restringido solo para el equipo…”
Yo: “Eso es muy vago. Dame algo más concreto. ¿Qué técnicas? ¿Cómo medís que funciona?”
Equipo de datos:”…”
Y ahí quedaba la cosa. Silencio incómodo. O peor: promesas genéricas que después nadie podía demostrar.
He vivido esa escena decenas de veces. Y lo frustrante es que todos tienen buenas intenciones. Los equipos de datos no están tratando de hacer algo malo, simplemente no tienen las herramientas para dar respuestas más sólidas. Y del lado de compliance, te quedás con esa sensación de “estoy aprobando algo que no puedo realmente evaluar”.
Ahora imaginate la misma conversación con JAX-Privacy en la mesa:
Equipo de datos: “Vamos a entrenar con privacidad diferencial usando JAX-Privacy. Acá te paso los parámetros: epsilon 8, delta 10^-6, batch size 2048, 100.000 pasos de entrenamiento. Acá está el log completo del accounting de privacidad. Y si querés, podemos correr auditorías empíricas del modelo para que veas que no está memorizando ejemplos individuales.”
No es perfecto. Todavía tenés que entender qué significan esos números (y sí, hace falta cierta curva de aprendizaje). Pero ya no estamos en el territorio de las promesas vagas. Estamos hablando de “parámetros específicos, logs auditables y evidencias que alguien puede revisar”.
Para alguien que trabaja como DPO o liderando proyectos de Data y IA, esto es como pasar de “confiá en mí, lo tenemos cubiero” a “acá están las cuentas, revisalas vos mismo”. Y en un mundo donde los reguladores cada vez piden más evidencia técnica concreta, donde el “nosotros hacemos las cosas bien” ya no alcanza, esto no es poca cosa.
Es cambiar radicalmente la dinámica de poder en esas conversaciones. Dejás de ser el que solo dice “no” por las dudas, y pasás a ser alguien que puede evaluar técnicamente si el riesgo está o no está controlado.
Y honestamente, después de tantos años sintiendo que aprobaba proyectos “a ciegas”, esto se siente como un alivio enorme.
Related Posts



Stay Informed With the Latest & Most Important News










Advertisement